rieszreg estimates the Riesz representer \(\alpha\) of a linear estimand \(\psi = \mathbb{E}[m(\mu)(Z,Y)]\) — the building block of one-step, TMLE, and DML inference — with gradient boosting (rieszboost), kernel ridge (krrr), random forests (forestriesz), or neural nets (riesznet). Think of it as the sklearn, tidymodels or superlearner for Riesz regression.
rieszreg ships built-in factories for ATE, ATT, TSM, additive shifts, local shifts, stochastic interventions, and arbitrary user-defined estimands; the squared Riesz loss plus the wider Bregman family (KL, Bernoulli, bounded squared); and sklearn-native tuning, model selection, and cross-fitting. Python and R, with bitwise-identical predictions on the same input.
What is Riesz regression?
You want to estimate some causal or structural estimand — say, the average treatment effect \(\psi = \mathbb{E}[\mu(1, X) - \mu(0, X)]\), where \(\mu(a, x) = \mathbb{E}[Y \mid A = a, X = x]\). A regression \(\hat\mu\) for \(\mu\) is biased; the standard fix uses a weight. For ATE, the weight is the inverse-propensity score:
Under the Riesz representation theorem, similar weights exist for many different estimands. rieszreg learns these weights directly from data: no propensity model, no truncation, etc. The same machinery handles continuous shifts, stochastic interventions, and many custom estimands a user can write down — for which closed-form weights could otherwise involve tricky or slow density estimates. These weights are then suitable for downstream use in weighting estimators or
For the longer derivation and a survey of the closed-form weights for each built-in estimand, see What is Riesz regression?.
Quickstart
Fit a Riesz representer for ATE on a synthetic binary-treatment dataset, select between two backends with cross-validation, and use the cross-fit \(\hat\alpha\) for a DML point estimate and Wald CI.
import osos.environ.update({"OMP_NUM_THREADS": "1", "MKL_NUM_THREADS": "1"})import numpy as npimport pandas as pdrng = np.random.default_rng(0)n =2000x = rng.uniform(0, 1, n)pi =1/ (1+ np.exp(-(-0.02* x - x**2+4* np.log(x +0.3) +1.5)))a = rng.binomial(1, pi)mu =5* x +9* x * a +5* np.sin(x * np.pi) +25* (a -2)y = mu + rng.normal(0, 1.0, n)df = pd.DataFrame({"a": a.astype(float), "x": x, "y": y})true_alpha = a / pi - (1- a) / (1- pi)
We start with a data frame df with treatment a, covariate x, outcome y. In this case, since this is simulated data, we know the true Riesz representer \(\alpha_0\) to evaluate against later.
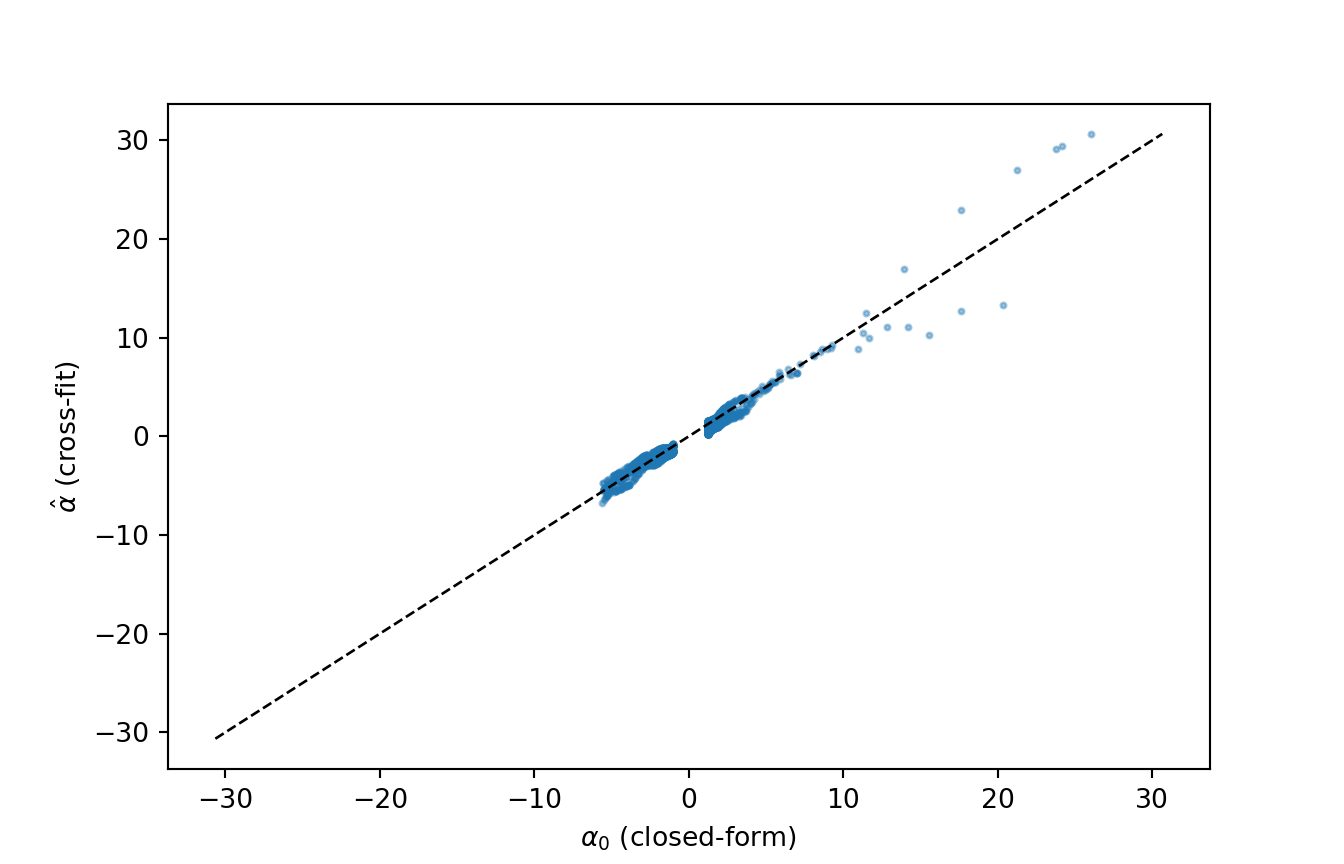
Wrap the candidates in a Pipeline and let GridSearchCV pick the winner via inner CV; nest that selector inside cross_val_predict so each outer fold runs its own inner model selection on the training portion only. The result alpha_hat is out-of-fold — every row was predicted by a model fit without seeing it.
Out-of-fold \(\hat\alpha\) vs the closed-form \(\alpha_0\) on the synthetic ATE DGP.
DML point estimate and CI
Cross-fit outcome regression
from sklearn.ensemble import GradientBoostingRegressormu_model = GradientBoostingRegressor( n_estimators=300, learning_rate=0.05, max_depth=3, random_state=0,)Z_full = df[["a", "x"]].to_numpy()mu_oof = cross_val_predict(mu_model, Z_full, df["y"].to_numpy(), cv=cv)# Counterfactual predictions need a model fit on the full data.mu_full = mu_model.fit(Z_full, df["y"].to_numpy())mu1 = mu_full.predict(np.column_stack([np.ones(n), x]))mu0 = mu_full.predict(np.column_stack([np.zeros(n), x]))
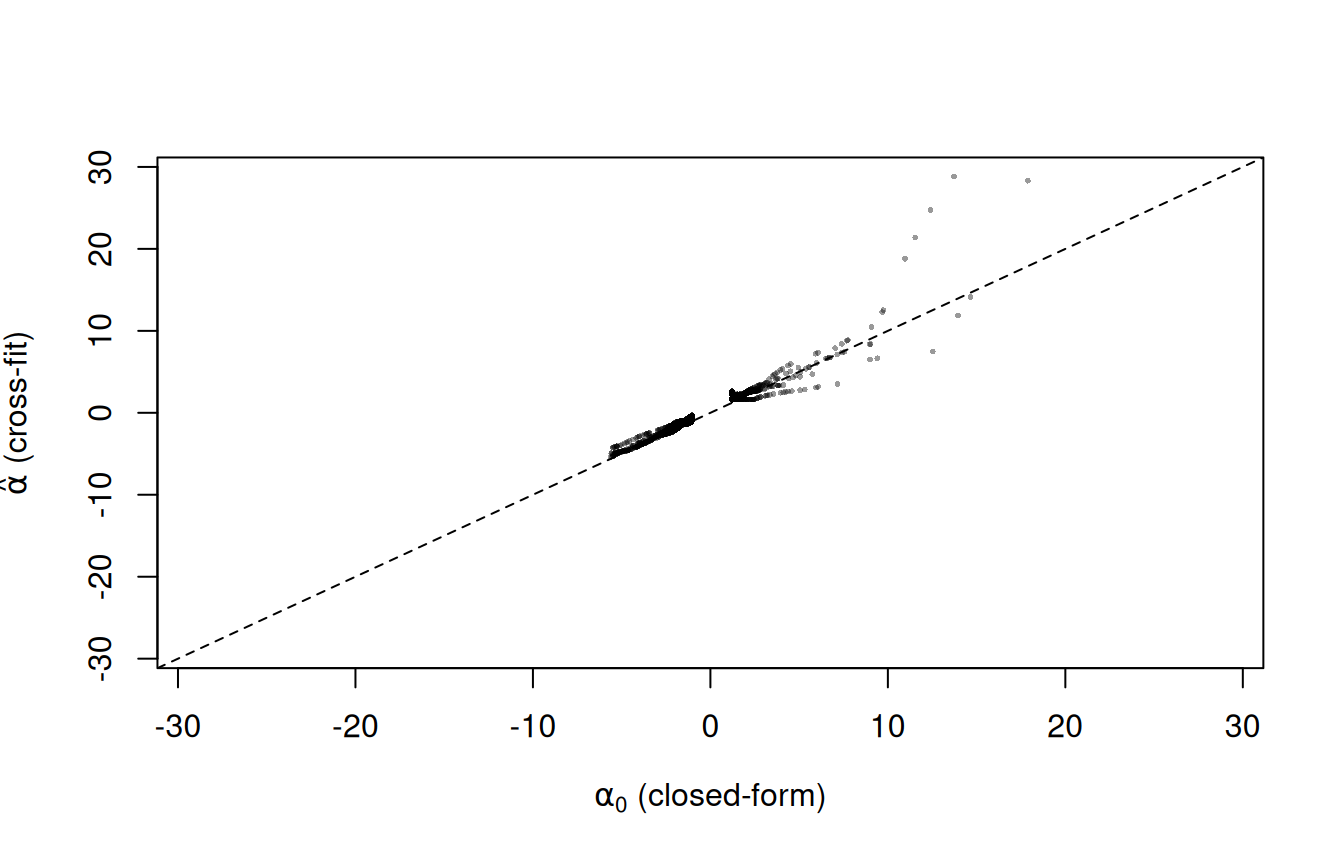
Use rsample (tidymodels) for fold splits, and a small loop for the nested cross-fit + per-fold model selection. Each outer fold runs its own inner-CV winner pick on its training portion only.
suppressPackageStartupMessages(library(rsample))cv_outer <-vfold_cv(df, v =5)alpha_hat <-numeric(nrow(df))for (split in cv_outer$splits) { tr <-analysis(split); te <-assessment(split); te_idx <-complement(split) cv_inner <-vfold_cv(tr, v =3) inner_score <-function(make) mean(vapply(cv_inner$splits, function(s) { m <-make(); m$fit(analysis(s)); m$score(assessment(s)) }, numeric(1))) best_make <-if (inner_score(make_boost) >=inner_score(make_net)) make_boost else make_net best <-best_make(); best$fit(tr) alpha_hat[te_idx] <- best$predict(te)}
Sanity check \(\hat\alpha\) against the closed-form \(\alpha_0\):
Out-of-fold \(\hat\alpha\) vs the closed-form \(\alpha_0\) (R).
Cross-fit outcome regression \(\hat\mu\) via xgboost, then assemble the DML estimate and Wald CI:
psi_ATE = 29.497
SE = 0.096
95% CI = [29.308, 29.685]
For TMLE on top of these nuisances, and integration with DoubleML and other downstream packages, see Estimation. For backend-specific tuning, see Backends.
TipCode execution
Every code block on this page ran at build time. The numbers and figures came from the version of rieszreg, rieszboost, krrr, forestriesz, and riesznet that produced this page.